阿尔法狗是什么算法(阿尔法狗是怎样的一只“狗”)

数据给你一双看透本质的眼睛,这里是《数据分析思维课》。
前面几节课给我们讲了各种各样的算法,分类、聚类、关联规则、蒙特卡洛、协同过滤、马尔可夫链……这节课是我们数据算法这章的最后一节课了,我们来聊聊到目前为止人工智能领域里的终极算法——深度学习算法。
现在一提到人工智能算法很多人就默认它是深度学习算法,其实严格意义上来讲,人工智能算法是涵盖了前面我们讲的所有算法的集合。也就是说,前面我们讲的所有算法都是人工智能算法的范畴(是不是一下子觉得高大上了)。人工智能、机器学习、深度学习之间的关系如下图。

人工智能算法历史与深度学习算法
说到人工智能,其实人类对这种智慧的追求已经有七百多年的历史了。最早可以追溯到 1308 年加特罗尼亚的诗人神学家雷蒙卢尔在《最终的综合艺术》(Ars GeneralisUltima)当中提到要用机械的方法从一系列的概念组合当中创造新的知识,这是有确切记载的类似人工智能想法最早的记录。
在 1726 年,英国小说家乔纳森斯威夫在《格列佛游记》里面提到一个叫做 Engine 的机器,这台机器放在 Laputa 岛上,可以运作实际而机械的操作方法,改善人的思辨和认知。最无知的人只要适当付点学费,再出一点体力,就可以写出关于哲学诗歌、政治法律数学和神学的书来。
后来在 1914 年,西班牙工程师莱昂纳多·托里斯克维多展示了世界上第 1 台可以自动下国际象棋的机器,当然水平那是相当差。而在 1921 年,捷克作家卡雷尔·恰佩克在他的作品《Rossum’s Univeral Robits》里第一次使用了 Robot 这个词,机器人开始进入人类的视野。
你能从这个发展史中看到,人类一直在寻求一套能够替代人类自身的机制。
到 1950 年,图灵发表了《Computing Machinery and Intelligence》其中提到了仿真游戏,这就是广为人知的图灵测试。图灵测试是指如果有一台机器能够与人类展开对话,且不能被辨别出来是机器的身份,那么就称为这个机器具有智能。
在 1956 年,马文·闵斯基、约翰·麦卡锡和另两位资深科学家克劳德·香农以及内森·罗彻斯特组织的达特茅斯会议里正式把人工智能提出来,自此 AI(Artificial Intelligence)的名字和任务得以确定。
在这之后几十年里,人工智能得到了飞速发展。在 1970 年,日本早稻田大学开发了一个可以控制肢体视觉和绘画系统的机器人 WABOT-1(下图左)。

在 1979 年,在没有人干预的情况下,Stanford 大学的 Stanford Cart 可以在房间内规避障碍物自动行驶,这相当于当时的无人驾驶系统。同一年早稻田大学发明了 WABOT-2,开始可以和人做简单沟通,阅读乐谱还可以简单的演奏普通电子琴(上图右)。
在 1997 年,IBM 研发的深蓝击败了人类象棋冠军卡斯帕罗夫。2011 年 IBM 研发的计算机沃森在 Jeopardy!击败了两名前人类冠军。同一年苹果发布了 Siri,可以给用户导航播报天气,还可以和用户进行简单的聊天。
2014 年 6 月 8 日,图灵测试终于被计算机尤金·古斯特曼通过。在场有超过 30% 的人认为它是一个 13 岁男孩。
2016 年谷歌 Deep Mind 研发出来的阿尔法狗击败了人类围棋冠军李世石。同年年底阿尔法狗以 master 为名横扫了各大围棋网站,取得 60 局连胜。与此同时,无人驾驶汽车开始纷纷上路。以美国加州为例,政府开始发放无人驾驶汽车牌照,允许具备一定技术能力的无人驾驶汽车厂商把无人驾驶汽车投入道路使用。700 年来,人类在追寻人工智能的道路上从未停歇。
最近 10 年出现可以打败人类自身的算法,是得益于 2006 年加拿大多伦多大学教授、机器学习领域泰斗、神经网络之父—— Geoffrey Hinton 和他的学生 Ruslan Salakhutdinov 在顶尖学术刊物《科学》上发表了一篇文章,该文章提出了深层网络算法,并在 2012 年利用 CNN 算法碾压了过去数年的分类等机器学习算法,取得 AlexNet 第一名,引起了人工智能的新一轮潮流。
CNN 和 RNN
还记得我们在分类算法里讲过,人类本身就是一个非常复杂的分类器。深度学习算法简单来说就是模拟人的脑神经网络来制造一个和人特别接近的分类器。它可以识别人们说的话、识别具体的视频中的图像内容,最终可以去应对各种各样的情况。
而现在最流行的两个深度学习的算法就是 RNN(Recurrent Neural Network)循环神经网络和 CNN(Convolutional Neural Network)卷积神经网络,它们都是模拟人脑的多个神经元多层次连接方式,通过大量反复的反馈和计算来实现最后效果。
我们先讲一下循环神经网络 RNN。你还记得前面课程里讲过一个特别能有效处理序列数据的算法吗?这种算法叫做马尔可夫链算法。
马尔可夫链只能够处理上一个状态到这个状态的选择,在一些事件的影响比较深远的时候它就无能为力了。而 RNN 算法可以针对更长的序列数据进行模拟和决策,例如我们去识别文章的内容或者去识别股票的价格的走势。
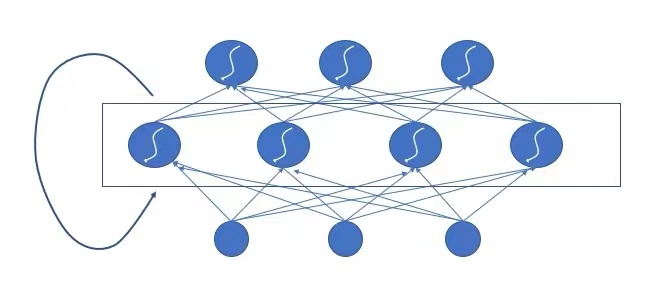
之所以 RNN 能够处理这种序列的数据,因为它其中有一个“反馈环”,能够模拟人脑使得前面的输入也能影响到后面的输出,相当于在模拟人脑当中的记忆功能。RNN 的整体模型结构就像下面这个图一样,是带着一个循环的神经网络结构。
当然这种算法的缺点也很明显,就是 RNN 就像是一个记性不好的人,只对最近的事情印象深,也就是说越靠后的数据影响比较大,而前期的数据影响很小。这样哪怕前期有一些很重要的教训和知识,这个算法它都记不住。于是很快就出现了一些变种的深度学习算法来弥补这个缺点,例如 LSTM 和 GRU 等等,这里你知道它们是来自 RNN 算法就可以了。RNN 算法被广泛地用于现在的语音识别机器翻译,例如我们使用的 Siri,背后其实就是利用了 RNN 的语音识别和对话系统进行训练。
和 RNN 不同的另外一种深度学习算法叫做卷积神经网络 CNN(Convolutional Neural Network)。它的特长是能够分层次地提取各种各样的特征,从而能够将大量的数据(比如大量图片和视频)有效抽象成比较小的数据量,而且不影响最后训练的结果。这样既能够保证原来图片和这些视频的特征,也不会在识别的时候占用巨大的计算资源。
CNN 其实模拟的就是人眼睛和头脑识别的原理。我们看到的世界其实是由各种各样的像素组成,而我们眼睛不会识别这些像素,而是会看到各种各样物体的边界,然后我们大脑会自觉把它们变成一些部件,把这些部件识别成到底是人脸还是物体。最后对人脸或者物体再调取记忆,识别出来这个人或物。
CNN 的抽象逻辑基本原理如下。
1. 卷积层神经网络,主要作用是保留图片的特征;
2. 池化层神经网络,主要作用是把数据降维,可以有效避免过拟合;
3. 全连接层神经网络,根据不同任务输出我们想要的结果。

所以 CNN 经常会被用来做我们的图片分类、检索视频的识别、目标的分割与识别。咱们现在比较火的抖音上面的美颜、让你变得年轻的组件、让你合成一些明星脸,这些其实都是使用的 CNN 的算法。我们在美国大片儿里面看到的黑客帝国的对决场面,它背后其实也是使用 CNN 的算法将目标进行切割出来的。

深度学习算法使用实例——AlphaGo
刚才我们简单介绍了深度学习算法的一些基本算法和概念,但当我们要真的要把深度学习变成人工智能的时候是非常复杂的,这个过程不是单一算法就可以满足。
我以 AlphaGo 为例,带你看看它是怎样用深度学习算法,组成了一个人工智能来打败人类的大师。
首先说一下为什么计算机下起围棋来非常难?因为所有的棋类的玩法基本上计算机都是通过探索每一种可能性,最后看到哪个可能性赢的概率最大。你可以参考一下下面这个表格,你会发现,围棋是最复杂的,需要 10 的 360 次方的计算才能够知道我们下一步应该怎么来做,这对于现在所有的计算机计算水平来说,基本都是不太可能,更何况围棋比赛有时间限制。

那么怎样构造一个围棋的算法系统来打败人类呢?其实任何一个算法在面对真正的实际问题时,我们都要有三步来走。
第 1 步,把问题抽象成计算机可以理解的问题。计算机并不能看懂围棋,他只能看得懂图片,不知道什么是输赢,更不知道怎么来计算每一步的优劣。所以第 1 步我们要把现实抽象成计算机可以懂的问题。
第 2 步,设计和选择整体的算法组合和方案。这一点就是 AlphaGo 的过人之处。
第 3 步,不断训练和调优。最终经过不断的打磨,让我们的人工智能算法超过人类。
我们更具体一点来说。第一步,我们先要让计算机理解围棋。我们看围棋的棋盘是一个 19×19 的线,一共有 361 个交叉点,然后每个交叉点上面可以有各种各样的黑子和白子。在围棋里面有气、眼,在某种规则情况下我们可以去提子,在某种情况下有禁着点。
刚刚说的是我们对于围棋的理解,那对于计算机来说,要怎么来理解这个围棋盘呢?
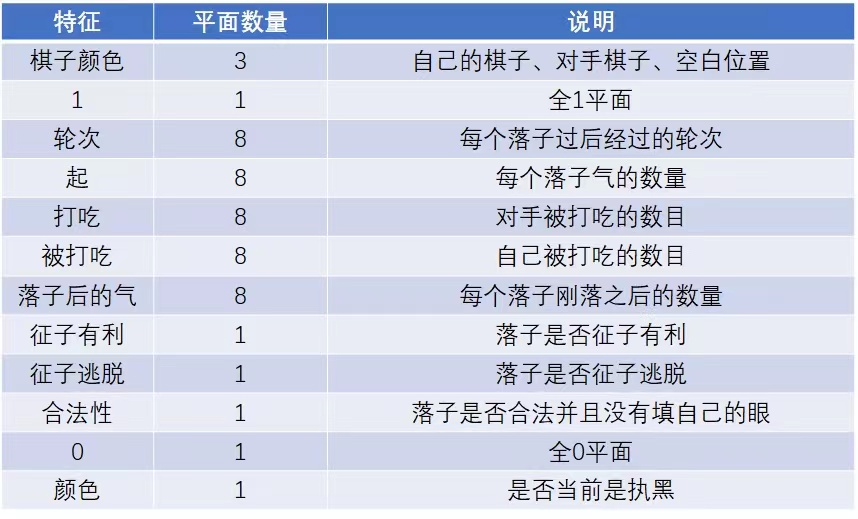
答案让计算机把每个点的数据都变成二维码,从棋子的颜色到围棋的气、轮次等等一共有 12 张二维码来代表此时此刻这个棋盘的状态。

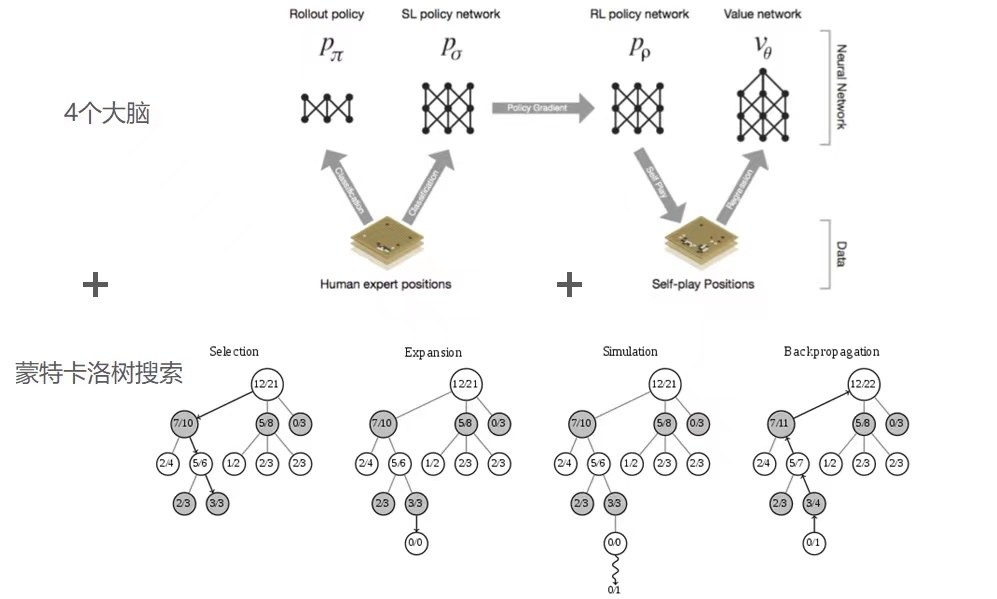
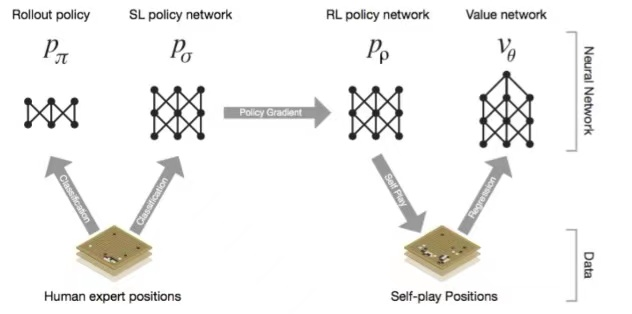
第二步,有了这些数据后,怎么来构造算法训练模型呢?AlphaGo 这点非常优秀,它不仅利用了我们前面讲到的 CNN 算法构造了快速感知“脑”、深度模仿“脑”、 自学成长“脑”以及全局分析“脑”四个大脑,还在这之上使用了蒙特卡洛树来优化整体的下棋策略。
这里面特别有意思的是,AlphaGo 开创了自学成长“脑”,它就像周伯通一样,可以左右手互搏,自己和自己下棋。所以,和人类下一盘棋后,他自己可以下无数次复盘的棋,24 小时不停地提高自己。整个 AlphaGo 算法很有意思,我用比较简单的语言总结在了咱们这节课的附录里,你如果感兴趣可以去看一下附录中的算法。
第三步,有了这些算法还不行,和所有人工智能算法一样,AlphaGo 就像一个小孩子,需要不断训练。于是 AlphaGo 团队的科学家们选择了网络对战,先后在 KGS、Crazy Stone、Zen 等网络平台上找高手对战,不停学习和迭代模型。在这几个平台都稳居第一之后,开始线下挑战人类的围棋冠军,这就有了 AlphaGo 和李世石的成名之战。
所以当我们遇到类似像围棋这种非常复杂的博弈类问题的时候,我们其实很难用单一的某种算法来解决。我们会做一个算法系统,发挥每一段不同算法的优势,最终得到我们想要的答案。所以阿尔法狗最终的形态是由 4 个深度学习算法的大脑,加上一个蒙特卡罗树搜索的算法组成的。
深度学习算法最新案例与未来
到现在,我们能看到深度学习不仅仅可以帮助我们建立一个可以打败人类的围棋算法模型,还可以做很多更前进的事情,比如可以模拟一个人去打王者荣耀。
也可以帮我们去实现自动驾驶和识别。

还可以学习人类去画水墨画,而且可以画的以假乱真。

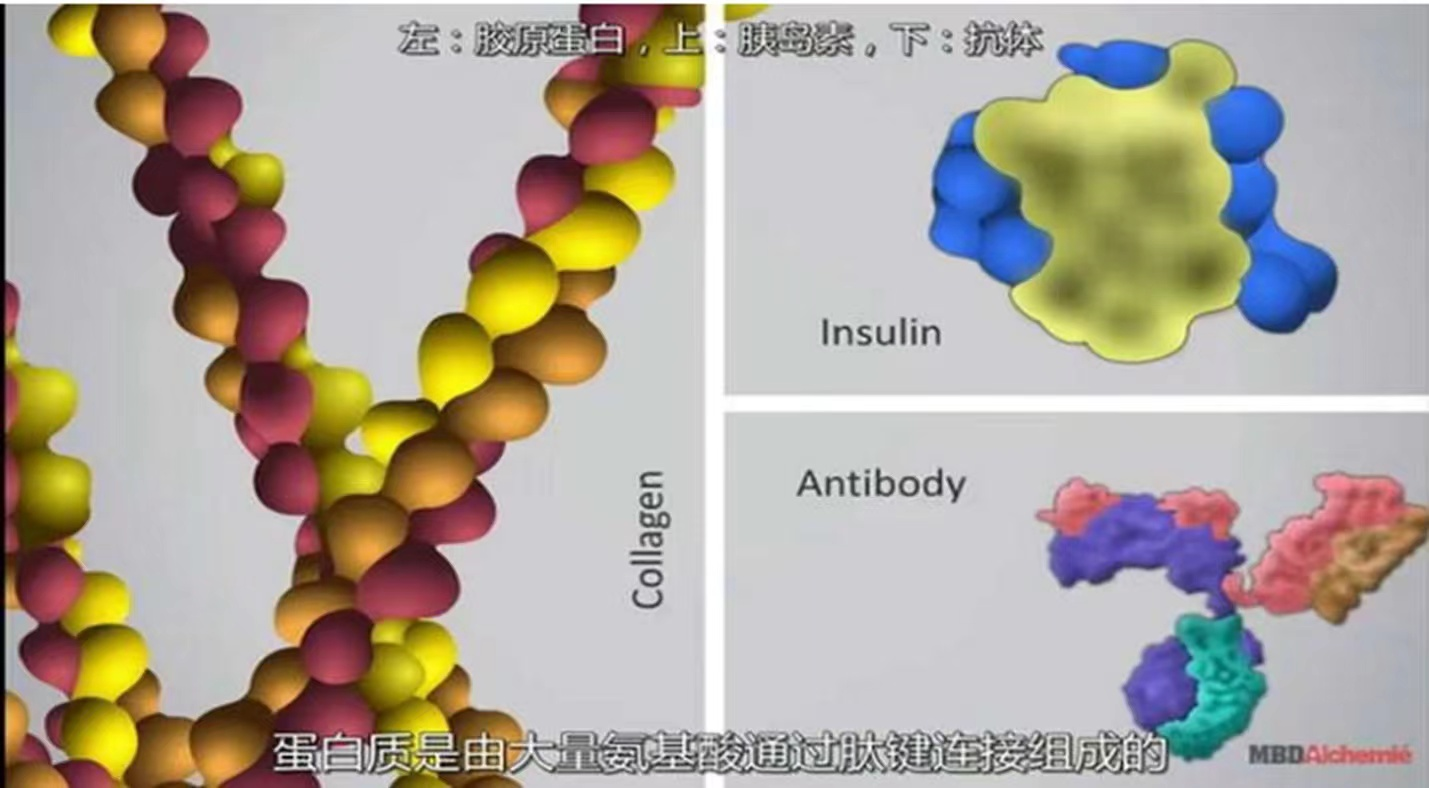
它还可以帮助人类去探索生命的根基,探索我们细胞内的蛋白质的结构变化,最终能够治愈现在所有的疾病,也许将来可以让人们永葆青春。
小结
到这节课为止,我们的算法章节也就告一段落了。你会发现,在人工智能的算法世界里,计算机正在以它的强大的计算能力不断去模拟和接近人类的判断。甚至在某些有规则的场景里,它可以完全超越人类。
由于现在我们的计算能力节节攀高,我们这一代人正在把过去七百多年来人类的幻想一步一步变成现实。深度学习算法会在我们所接触的一切领域里面发挥颠覆性的作用,如果你的工作还是基于规则的重复劳动没有丝毫创新,那么你所做的工作很有可能将来就会被某一个人工智能的算法所替代。
尽管人工智能算法可以在很多有规则的竞争里超过人类,甚至现在很多人对人类十分悲观,觉得总有一天人工智能会像电影里那样奴役人类,但我一直都不这样认为。因为人工智能算法是没有灵魂的,因为它所有的计算其实本质上还是一个分类模拟器。
人工智能算法是一个有监督的学习算法,无论通过什么样的方式去模拟,它都无法通过一个有规则的算法去适配当今无规则的现实世界,更无法去模拟人们的感情、灵感和创造力。所以我们不要“机械”地活着,要往生活里多注入一些热爱和创新才好。数据给你一双看透本质的眼睛,算法让你看清数据背后现实世界的规律。
思考
你所见的场景里,还有哪些是用人工智能的算法打败人类的?你认为它打败人类的优势是什么?欢迎你在留言区分享,我们共同提高。
附录:文科生也可以读懂的 AlphaGo 算法
现在我们把正文里的 AlphaGo 算法进一步展开。第一步,我们先要让计算机理解围棋。我们看围棋的棋盘是一个 19×19 的线,一共有 361 个交叉点,然后每个交叉点上面可以有各种各样的黑子和白子。在围棋里面有气、眼,在某种规则情况下我们可以去提子,在某种情况下有禁着点。
刚刚说的是我们对于围棋的理解,那对于计算机来说,要怎么来理解这个围棋盘呢?
AlphaGo 采用的是一个非常聪明的做法,它把 19×19 的棋盘里面每个地方都标上了 12 个数字,每一个数字其实都是有不同的含义。你可以这样理解,计算机把这个棋盘变成了 12 个 19×19 的二维码,叠加到一起,变成一个计算机图像去做识别。这样的话,我们就把它变成了计算机可以看懂的棋盘了,你可以参考下表。
第二步,在我们让计算机看懂了这个棋盘之后,我们要设计一个算法系统,让他可以打败人类,这是 DeepMind 设计 AlphaGo 最核心的地方,他们用的不是一个算法,他们给 AlphaGo 设计了 4 个大脑,也就是实际上有 4 个不同的算法来支撑这个打败人类的“狗”:
- 快速感知“脑”:Rollout Policy ,用于快速的感知围棋的盘面,获取较优的下棋选择,类似于人观察盘面获得的第一反应,准确度不高;
- 深度模仿“脑”:SL(Supervised Learning) Policy Network ,通过人类 6-9 段高手的棋局来进行模仿学习得到的脑区。这个深度模仿“脑”能够根据盘面产生类似人类棋手的走法;
- 自学成长“脑”:RL (Reinforcement Learning)Policy Network 以深度模仿“脑”为基础,通过不断的与之前的“自己”训练提高下棋的水平;
- 全局分析“脑”:Value Network,利用自学成长“脑”学习对整个盘面的赢面判断,实现从全局分析整个棋局。
他们背后都是使用的 CNN 网络来进行训练的,但是使用的方法各不相同。快速感知脑(Rollout Policy) 网络比较简单,要求落子速度更快,但准确率更低。
深度模仿脑(SL Policy Network)是有监督的神经网络,就像分类算法一样,以人类棋手的对弈记录进行训练,越和人类接近,证明这个模型越好。这个网络训练出来就是集人类棋谱和棋局的集大成者。
但是如果只是如此,AlphaGo 还是无法超越人类的。于是就有第 3 个大脑:自学成长脑(RL Policy Network)。这个大脑就像周伯通的左右手互搏一样,它是模仿一个新的对手,自己和自己开始对弈,如果自己把自己赢了,那么就以赢的这一局的结果来训练自己而不是人类的棋谱训练自己,这样不断更新的自己的权重。
这样 AlphaGo 自己左右手的这两个算法都越训练越好,所以说人类无法打败阿尔法狗,因为它一天 24 小时不停地在几千万次地训练自己,而人的大脑没有那么多的时间和容量来训练这件事情。
最后一个是全局分析脑(Value Network),这其实就是训练每一个旗面的胜率到底是怎样,通过前面自我博弈的这些棋局的数据来训练一个棋面胜率。那它为什么不用人类棋手对局来做这种价值训练呢?因为人类的对局数据很少,也就意味着有效样本很少,很容易出现前面咱们讲过的“过拟合”。所以它通过周伯通自我博弈的各种招式去看,到底我们这场比赛现在这个阶段的价值是好还是不好。
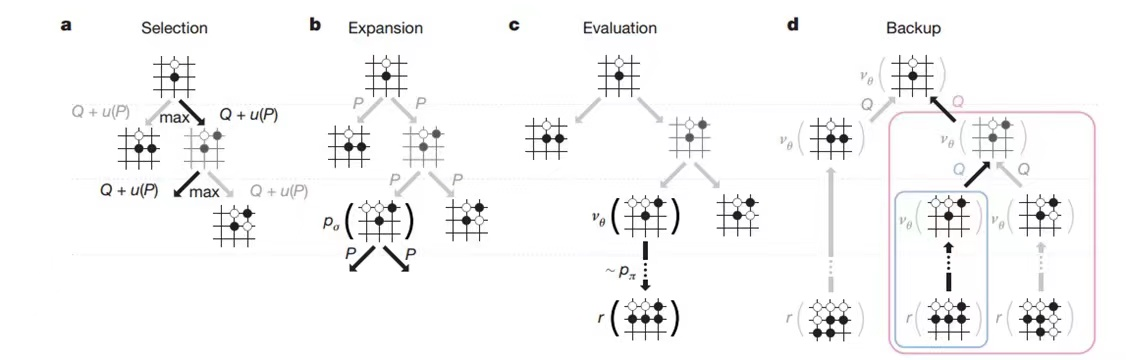
的确,如果给无限长的时间的话,AlphaGo 这个四脑狗一定可以打败人类,但是你知道真正在下围棋的时候,每个选手旁边都有一个闹钟要记录他自己所用的时间,时长最长为每方 6 小时。所有比赛都会保留读秒时间,超时就会判负了。
所以这是在一个有限时间里面,我们要面对 10^360 次方的可能性计算。
这怎么办呢?这里就提到了前面我们所学的一个知识,在无限多的可能性里面找到近似于最优解的算法,它就是蒙特卡罗算法。我们这里使用这种算法解决我们下棋问题的时候,我们使用的就是蒙特卡罗搜索树。
你可以回顾一下蒙特卡罗算法的特点,它就是在一个大苹果布袋里面挑苹果,每次把这个比较好的苹果留下来,不好的苹果扔掉。在时间结束的时候,每次的结果不一定是全局里面最优的这个解,但一定是跟你当前消耗时间类似的情况下,相对比较好的结果。
整体来讲,这个 AlphaGo 的蒙特卡罗树会通过 4 步来确定一个比较好的结果:
- 通过选择模拟下一步要走的子;
- 通过扩展模拟走子策略;
- 评估来看走子效果;
- 回溯来把结果向上传递。
这样就可以在有限时间内让四个大脑找到相对最优解。同时这里面的一个关键点在于,深度学习消耗的算力和时间是和它面对的问题复杂度成指数增长的。所以如何拆解问题、如何有效使用蒙特卡洛算法,往往是一个人工智能系统的关键。
第三步,先学习人类现有的棋谱和所有人类对战的历史,然后在网上和围棋爱好者进行对战,然后开始线下和围棋高手进行对战:
1. 初始训练:KGS;
2. 模拟对手:Pachi;
3. 模拟对手:Crazy Stone;
4. 模拟对手:Zen;
5. 模拟对手:Fuego;
6. 人类对手:Fanhui(欧洲冠军);
7. 人类对手:李世石;
8. 人类对手:柯洁。
注意,这里不仅学习对象是各种各样的对手,因为 AlphaGo 还有左右手互搏算法的存在,其实它是不停在 24 小时对战和复盘,提高自己的水平。最终 AlphaGo 打败了人类的围棋冠军。
总结下 AlphaGo 这个狗的全貌,在面对围棋这种非常复杂的博弈类问题的时候,我们其实很难用单一的某一种算法来解决它。我们会做一个算法系统,发挥每一段不同的算法的优势,最终得到我们想要的答案。